Digital Émigré – Compiling a Small Data Set for the Study of the Russian Periodicals in Emigration
June 22, 2017
This blog post documents how I compiled the dataset for my dh project about the periodicals of the Russian emigration in the 1970s and 1980s. This post provides a detailed discussion of the methods and principles which guided the process of compiling and editing the data that I used for my article “Soviet Union on the Seine: Sintaksis, Kontinent and the Social Life of Journals in Emigration”) (forthcoming in Russian Review). I provide practical details about the tools I used in the process, hoping that they may prove helpful to other researchers interested in pursuing similar research projects.
1. General Aims and Motivations for the Project
2. Compiling the Data
a. Extracting (Optical Character Recognition and Regex
b. Cleaning (OpenRefine)
c. Normalizing (VIAF)
3. Preparing the Data for Network Analysis
General Aims and Motivations for the Project
At the moment, Digital Émigré, a data repository for the periodicals of the Russian emigration, consists of two data sets: the contribution-level metadata of the two US-based journals Novosl’e and Novyi amerikanets and of the Paris-based periodicals Kontinent (founded by Vladimir Maksimov in 1974) and Sintaksis (founded by Maria Rozanova and Andrey Sinyavsky in 1978).
The Kontinent-Sintaksis data can be found as CSVs on Github and interested researchers are welcome to use it for their research, citing the related article in Russian Review. This blog post documents the aims, methods, methodological and practical challenges of the compilation of the Sintaksis-Kontinent dataset.
The dataset, consisting of entries for the contributions to and authors of each individual journal issue. It provides material for the exploration of communities of authors around these two journals. Quantitative insights to be gathered are concerned with the social constitution of periodical publications: the frequency and the extent to which authors contributed to one or more than one journal. What underpins this approach is a notion of periodicals as facilitators of social networks of authors.
Sintaksis and Kontinent are an interesting test case for digital approaches to periodical studies for three reasons:
- The cases are well known among scholars of the Russian emigration for their antagonistic relationship, which deserves a more thorough and critical investigation. Toward this end, the dataset can contribute a new approach of study of editorial practice as social and intellectual strategies.
- The data of the two journals is manageable in scope. There were 33 issues of Sintaksis between 1978 and 1992 and 73 issues of Kontinent between 1974 and 1992. In this period, the periodicals featured more than 1,000 authors and more than 3,500 contributions. Thus, the dataset is large enough to yield quantitative insights, but small enough to allow a constant return to close readings of the text.
- The journals have already been digitized by imwerden and vtoraya literatura, two digitization projects that provide ample material to the computational study of Russian literature. As bibliographical data, the information extracted from the tables of content does not fall under any copyright restrictions.
The first step before any analysis was compiling the data: extracting it from the digitized tables of contents, transferring it into spread sheet format with individual columns, finally normalizing author names. For each individual step, specific tools and software suits were used. It is important to keep in mind that already at this stage important editorial and interpretational decisions are made.
Extracting
Since the digitized pages were machine readable only in part, I ran them through a text recognition software first. At a price of about $100/license, Abby Fine Reader is a fine piece of software for language recognition that will produce reliable text files based on images of text. From the standpoint of computation, this isn’t the most trivial thing. I’m mentioning this not to advertise, but simply to put into relation the economics of dh research. It’s not a very steep price and libraries often own copies. Still, it’s a thing to be factored in into grant writing, the search for collaborators, etc.
While Abbyy Fine Reader does an excellent job with Russian, switches between languages in one text remain a challenge. The switch between languages and scripts occurs fairly frequently in émigré periodicals, as they recruited western contributors, mentioned place names etc. Abbyy can produce some mix ups between Cyrillic-Latin letter cognates. I relied on closely monitoring a few test pages, adjusting the settings and proceeding with the rest of the pages, which generally yielded good results.
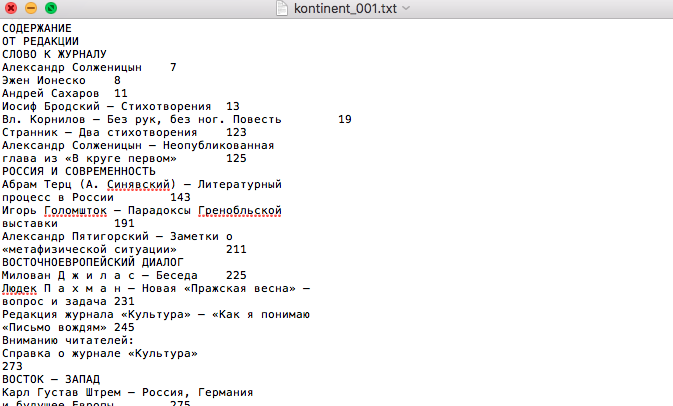
An Image of the Table of Contents of the Journal Kontinent. Displayed as Plain Text Produced with Character Recognition Software Abbyy Fine Reader
Cleaning
The product of working with the character recognition software were 100 text files of tables of content like the one captured above. This is the moment for regular expressions, aka basic sorcery. Regular expressions (or: regex) basically function like Microsoft Word Find and Replace on steroids. I opened my files in a text editor that’s good at supporting regex – I used Oxygen. You may prefer another one.
If you look closely, you’ll notice many of regularities even within this messy txt. There’s always a “ – “ between author and contribution. I replaced all of those with an ” @ “, a placeholder that’s very easy to see and certainly didn’t come up in the documents. However, you may also have noticed this entry:
Людек П а х м а н – Новая «Пражская весна» –
Вопрос и задача 245
Since the “ – “ is part of the title, I didn’t want this to end up as:
Людек П а х м а н@Новая «Пражская весна»@
Вопрос и задача 245
This is the strength of regular expressions, because they let us determine specific contexts that should apply – here only before titles of contributions, which all happen to start in capital letters (with one exception). Using the following regular expression will yield the appropriate results:
Find:
— ([А-Я])
“[А-Я]” refers to all capital letters between А and Я in the Cyrillic alphabet. Using “( )” marks it as a capturing group, which allows us to reference it in the following replace statement as $1 – $ being the general marker for a capturing group in the find command and 1 telling us it is the first one of those groups. Thus, the replace command is:
Replace:
@$1
This way, I parsed out all kinds of things, for example the page numbers, which are always one to three numerals in the end of a line. Here, the regex Find and Replace would be:
Find:
([0-9]{3})$Replace:
@$1
You already know “( )” and can make sense of “[0-9]” based on “[А-Я]”. “{1,3}” means that the numeral comes up between one and three times and $ marks the end of the line.
I could go on at length about other steps to parse this data, but I think the idea as such has become clear. Every data set will need different solutions that can be established through a process of discerning regularities, choosing appropriate regular expressions, trying them out in one document and then applying them to the rest of the documents that look the same. If you google “regex cheat sheet,” you will find plenty of inspiration for this.
Finally, I replaced all of my @ with tabs, saved the file as tab-separated values (.tsv format) and opened them as tables in Google sheets, which represented all information in neat columns. A word of warning should be said here about using Microsoft Excel, which can easily end up messing with the representation of Cyrillic characters. I’m sure there are fixes to the problem, but in Google sheets I never encountered them in the first place. I ended up with something like this:
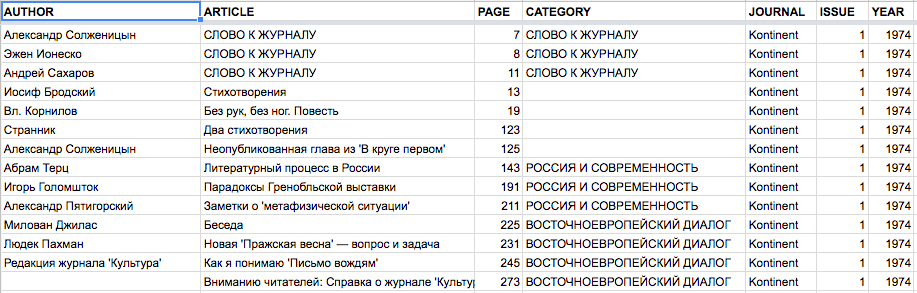
The Table of Contents of Kontinent 1, Displayed as a Google Spread Sheet
You’ll notice, I added a column for the name of the journal, issue and year, because those were crucial for the quantitative evaluation. I also parsed out what section of the journal the contribution was in.
This is where the editorial decision can have strong implications research questions. I think it’s valuable to capture additional data if it is there, like the journal section that to a certain extent also speaks to the genre and meanings of a contribution. However, I would try to avoid the thin ice of adding data layers based on preliminary interpretations of the data – such as decisions about the genres of texts (review vs. op-ed vs. political essay, poem vs. prose), themes or intended audiences (western vs. Soviet dissident vs. emigration). I have serious concerns about the integrity of such a data set. How would you define Gogol’s “poema” Dead Souls or Solzhenitsyn’s Ivan Denisovich – a povest’ according to the author, a novel according to the journal Novyi mir and many western publishers.
If later on someone decided to do a quantitative analysis of the distribution of genres or audiences, it would really be an analysis not of the journal but of my interpretation of the journal. If nothing else, the creation of such a data set with preliminary interpretations of the material warrants the definition of very consistent criteria and thorough documentation thereof.
Normalizing with OpenRefine and VIAF Authorization
If you look back at the rough data in the txt format, you’ll notice another problem with the entry for Людек П а х м а н. For some reason, the editors put it down with odd letter-spacing. Later on in the data, the name comes up again as Пахман. For the dataset however all names need to be exactly the same. In order to later use the data for network visualizations, we need to make sure that every concept in reality is referred to in the same way – at least for now. OpenRefine (also known as Google Refine) is a tool that is made for just this purpose. One of the great affordances of this data cleaning tool is text faceting and clustering. There are excellent tutorials on the internet, so I will not go into detail, but just mention the key steps used for the Sintaksis/Kontinent dataset and bring up one editorial caveat that is very typical of the challenges humanities material brings to quantitative analysis.
First of all, clustering allows us to bring all similar terms together and choose the same name for them. For Пахман, it would like this:
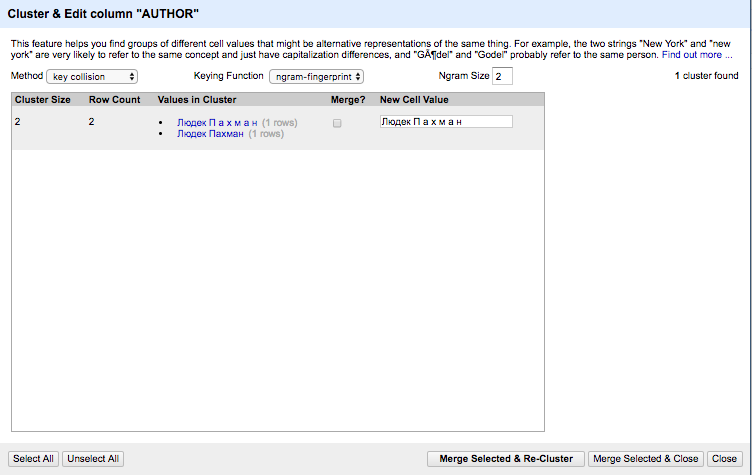
Screenshot of Clustered Values in Open Refine
But even if we now select that his name be Людек Пахман rather than П а х м а н in all incidents, this might not be sufficient. Luděk Pachman was a Czechoslovak political activist (and chess grandmaster) who lived in West Germany since 1972. There’s really no reason to represent his name in its odd Cyrillic transliteration in the first place. Moreover, I wanted other people to be able to use my dataset toward whatever research purposes they may deem meaningful. I want those people to see without any doubt what Luděk Pachman I am referring to.
This is were name authorization comes into the game, specifically the Virtual International Authority Files. It is a name authority service, where every historical person who has published enough to be registered by libraries receives a unique ID. Well, nearly unique, because some national libraries have contributed double entries especially for Russian authors, possibly because they failed to recognize the names in other transliteration systems. As a rule, I went with the entries that were shared by a large number of national libraries. In the case of Pachman, I’d pick the first entry, rather than the once made by the Portuguese national library or what seems to be a double entry created by the German national library.
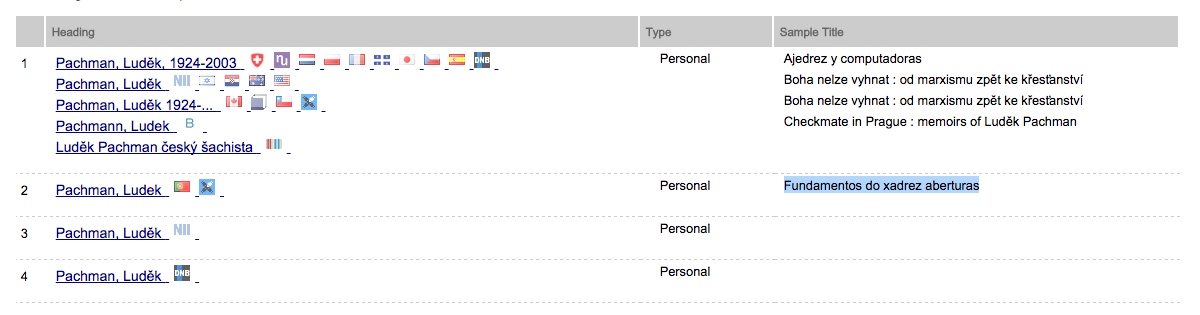
Screenshot of the VIAF entries for Luděk Pachman
The second, intellectually more challenging caveat is the following one. In my dataset, there are authors who published under various pseudonyms – mostly famously Andrey Donatovich Sinyavsky and his alter ego Abram Tertz. Obviously, OpenRefine clustering would not put these two names together, but VIAF certainly considers them as belonging to one historically concrete person. In the context of humanities research, this might not always be meaningful.
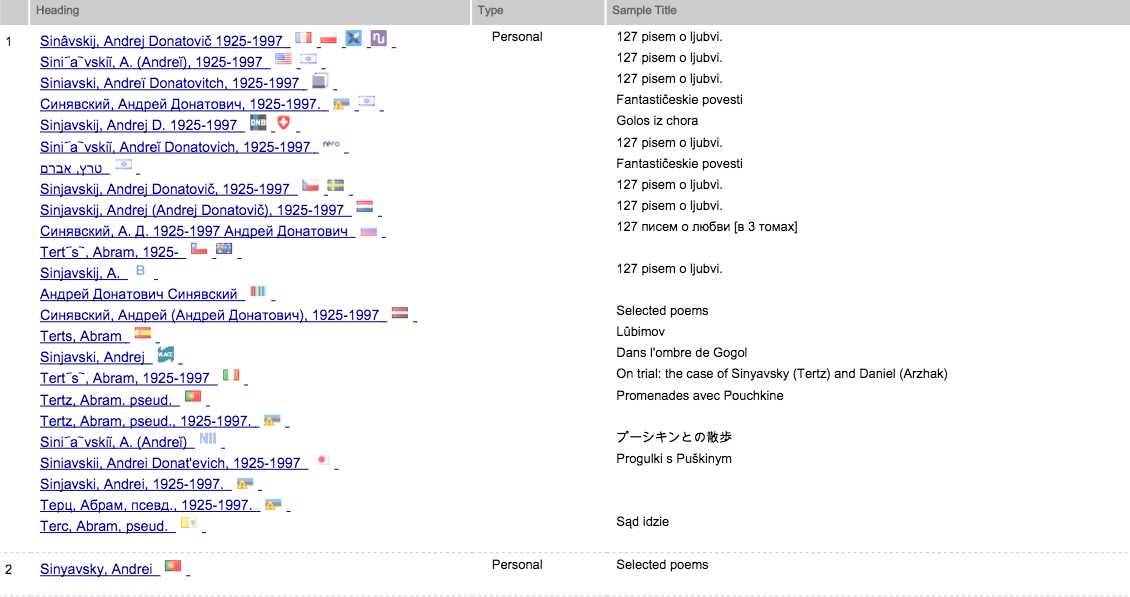
Screenshot of VIAF Entries for Andrey Sinyavsky
This may be all good (with the exception of the second, double entry for Sinyavsky) from the library standpoint of seeking the historically concrete author of a text. But from the standpoint of the culture of the third wave emigration, it’s not that simple. For the Soviet dissidents, pseudonyms were sometimes part of an elaborate hide and seek game with the authorities and often enough a matter of plain survival. For Sinyavsky, this was certainly the case when he had to face a prison camp sentence for his texts published in the west under the name of Tertz since the late 1950s.
Sinyavsky continued to use both names for his publications even after he had emigrated. Clearly, the use of these names have some significance and it was important to me to maintain this idea in the data. Ultimately, my research is concerned not with biographies or individual authors, but with the ways in which intellectual communities were artfully crafted and moderated by journals in the west. The play with pseudonyms is significant in this context and Sinyavsky is not the only case. So I opted to create two unique names for the multiple identities of some authors, in defiance of the conventional approach of VIAF.
3. Preparing the Data for Network Analysis
For my article “Soviet Union on the Seine,” I was particularly interested in the idea of viewing journals as social networks. Generally speaking, a network consists of things (in the language of network analysis: nodes) and connections between the things (in the language of network analysis: edges). The most basic way to represent journals and authors is a bimodal network, i.e. a network that has two kinds of nodes: contributors and journals. The act of contributing (or being featured in a journal – depending from your perspective) constitutes a connection. The frequency of contribution determines how strong the connection is.
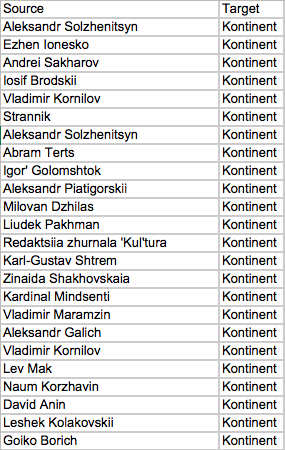
Beginning of the Egde List for a Bimodal Network of Sintaksis and Kontinent
I used the software Gephi to create the network visualizations, but have since switched to Cytoscape. Both are open source and both have basically the same functionalities. You give them an edge list and they return you a network graph. (For an excellent introduction into Cytoscape, check out Miriam Posner’s tutorials.)

Bimodal Network Graph Pointing to the Shared Authors (Represented by the Black Nodes) between the Two Journals Sintaksis and Kontinent
This is one of the first graphs I made and it became my starting point of further enquiry into the data and the text of the journals, because it refuted the idea that those two journal existed in mutually exclusive realms, when they actually shared a significant number of authors.