Automatic Transliteration in Open Refine
September 13, 2017
As I mentioned in earlier posts, I love using Open Refine for my data cleaning. For my project Soviet Journals Reconnected, I wanted to add transliterated names to my database. Transliterating by hand is out of question. For a while, I used a somewhat inconvenient Python script I had come up with.
But even for automatic transliteration, Open Refine is your best friend. My database uses the Library of Congress transliteration. I know some people feel strongly about it, since it is not “scholarly” enough, replacing several Cyrillic characters with the same Latin character (“i” for “и” and “й”), while other Cyrillic characters are represented by clusters from the Latin alphabet (“iu” for “ю” and “shch” for “щ”). However, I really like the simplicity of living completely without diacritics (think of the German standard transliterations “č”, “š,” etc. I can see a lot of potential trouble with that on the command line and I’d rather avoid it from the very beginning).
Transliterating in Open Refine just takes a few steps.
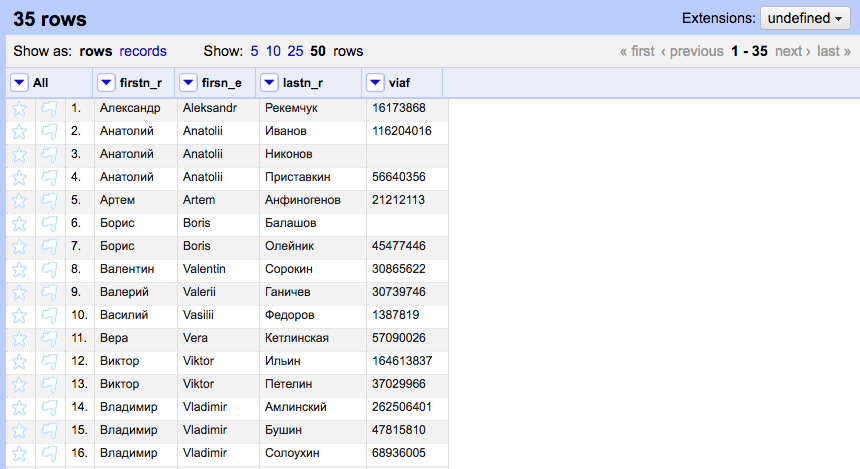
We start with a table that has information in Cyrillic script:
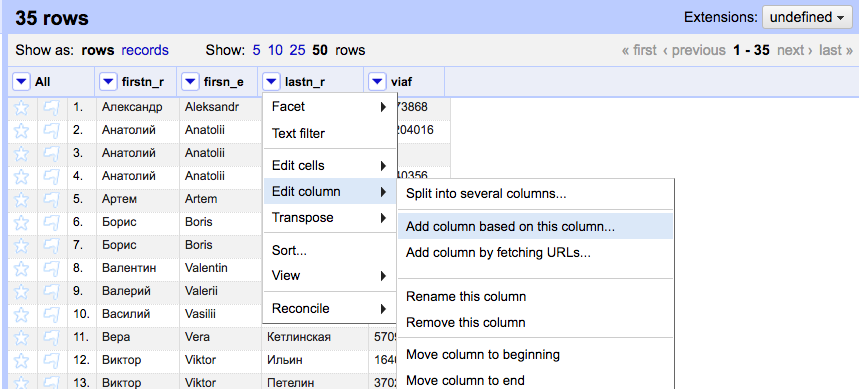
Choose “Add Column Based on This Column:”
Finally, use the following GREL expression to transform the values. (Copy and paste from below):
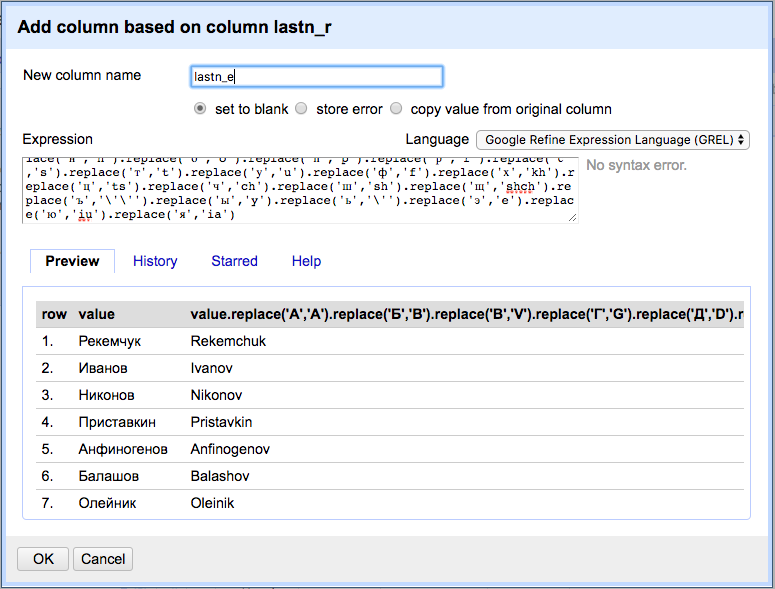
You probably figured: this is a very basic find and replace where every single Cyrillic character is replaced with its Library of Congress transliteration. And it goes like this:
value.replace(‘А’,’A’).replace(‘Б’,’B’).replace(‘В’,’V’).replace(‘Г’,’G’).replace(‘Д’,’D’).replace(‘Е’,’E’).replace(‘Ё’,’E’).replace(‘Ж’,’Zh’).replace(‘З’,’Z’).replace(‘И’,’I’).replace(‘Й’,’I’).replace(‘К’,’K’).replace(‘Л’,’L’).replace(‘М’,’M’).replace(‘Н’,’N’).replace(‘О’,’O’).replace(‘П’,’P’).replace(‘Р’,’R’).replace(‘С’,’S’).replace(‘Т’,’T’).replace(‘У’,’U’).replace(‘Ф’,’F’).replace(‘Х’,’Kh’).replace(‘Ц’,’Ts’).replace(‘Ч’,’Ch’).replace(‘Ш’,’Sh’).replace(‘Щ’,’Shch’).replace(‘Ъ’,’\’\”).replace(‘Ы’,’Y’).replace(‘Ь’,’\”).replace(‘Э’,’E’).replace(‘Ю’,’Iu’).replace(‘Я’,’Ia’).replace(‘а’,’a’).replace(‘б’,’b’).replace(‘в’,’v’).replace(‘г’,’g’).replace(‘д’,’d’).replace(‘е’,’e’).replace(‘ё’,’e’).replace(‘ж’,’zh’).replace(‘з’,’z’).replace(‘и’,’i’).replace(‘й’,’i’).replace(‘к’,’k’).replace(‘л’,’l’).replace(‘м’,’m’).replace(‘н’,’n’).replace(‘о’,’o’).replace(‘п’,’p’).replace(‘р’,’r’).replace(‘с’,’s’).replace(‘т’,’t’).replace(‘у’,’u’).replace(‘ф’,’f’).replace(‘х’,’kh’).replace(‘ц’,’ts’).replace(‘ч’,’ch’).replace(‘ш’,’sh’).replace(‘щ’,’shch’).replace(‘ъ’,’\’\”).replace(‘ы’,’y’).replace(‘ь’,’\”).replace(‘э’,’e’).replace(‘ю’,’iu’).replace(‘я’,’ia’)
The concept should work for other non-Latin scripts as well. Have you used it and found it useful? Or do you have suggestions to make it easier? Let me know in the comments section.